Build a ChatGPT search plugin with Notion and Pinecone
In this tutorial, you will use Langchain, a JavaScript package for working with large language models, and Pinecone, a vector database, to index a Notion workspace. You will then be able to query your Notion workspace using a custom ChatGPT plugin built with Cloudflare Workers.

Prerequisites
Before you start, make sure you have:
- A Cloudflare account. If you do not have one, sign up before continuing.
- Node.js and npm installed on your machine.
- Access to a Notion workspace and an integration token.
- An OpenAI API key.
- A Pinecone account and API key.
1. Create a Worker application
First, use the c3 CLI to create a new Cloudflare Workers project. You can use the ChatGPT plugin template to start:
$ npx create-cloudflare-cli --template chatgpt-plugin <PROJECT_NAME>
Replace <PROJECT_NAME> with your desired project name. This will create a new project directory with the specified name and place the ChatGPT plugin template files in this directory.
2. Create a Pinecone index
Pinecone provides vector indexes, which are databases that stores your data as vectors, and allows quick querying and retrieval. In this tutorial, you will use a free Pinecone index to store the relevant vectors for your Notion workspace.
To begin, create a Pinecone account. In this tutorial, everything you build will be storable in the free tier. Once you have created an account, you will then need to wait a few minutes for your project to be created.
In your Pinecone project dashboard, create a new index. Pinecone’s definition of an index:
An index is the highest-level organizational unit of vector data in Pinecone. It accepts and stores vectors, serves queries over the vectors it contains, and does other vector operations over its contents.
Give your index a name (for this tutorial, use the name example-index). In the index configuration, enter a dimension value of 1536. This is a typical value used in many AI applications, and is the format used by a tool you will later use – OpenAI’s embedding API.
Once your index is created, take note of the following configuration values for use later in your application:
PINECONE_API_KEY: A unique API key that allows you to read/write to your Pinecone indexes. You can find this in your Pinecone project dashboard under the API Keys section in the sidebar. You may need to create a new API key if you do not have one already.PINECONE_ENVIRONMENT: The environment that Pinecone deploys to. This generally includes a region and a number, such asasia-southeast1-gcp-free.PINECONE_INDEX_NAME: The name of the Pinecone index you just created. In this tutorial, use the nameexample-index.
3. Set up your Notion Workspace
Once your Pinecone database is ready, you will need to configure your Notion workspace and create an application.
Due to the way ChatGPT (and large language models in general) understand and process data, it is worth taking a brief moment to look at your Notion workspace and how it is structured. Retrieval in a ChatGPT plugin from a Notion workspace, or any data in general, is best suited for highly structured data. Due to Notion’s flexibility, you may find that your content in Notion is naturally unstructured, which can cause problems particularly when querying your data via Pinecone.
Because of this, it may make sense to expose a small subset of your Notion workspace to Pinecone – for example, an important database or section of your workspace – instead of everything in the entire workspace.
To begin integrating your Notion content, create a new Notion application at developers.notion.com. Create a new integration (with any name of your choice), and make sure to select the Internal Integration option. This will allow you to read and write to your Notion workspace.
Next, you will need to grant your integration access to your Notion workspace. To do this, go to the Internal Integrations section in the sidebar, and select the integration you just created. You will then need to grant your integration access to your Notion workspace. To do this, select the Authorize, and select the workspace you want to index.
Finally, you need to share your Notion workspace with your integration. To share your Notion workspace with your integration:
- Go to the page you want to index, and select the “…” menu in the top right corner.
- Find the section called Connections, and the submenu called Add Connections.
- In this menu, find your new integration and select Add. This will share the selected page with your integration.
Now, take note of the following configuration values for use later in your application:
NOTION_INTEGRATION_TOKEN: A unique token that allows you to read/write to your Notion workspace. Find this in your integration dashboard under Internal Integration Tokens in the sidebar. You may need to create a new integration token if you do not have one already.NOTION_PAGE_ID: The ID of the Notion page you want to index. Find this by going to the page you want to index, and copying the ID from the URL. For example, if your page URL ishttps://www.notion.so/My-Page-Name-1234567890abcdef1234567890abcdef, your page ID is1234567890abcdef1234567890abcdef.
4. Index Notion content with Langchain and Pinecone
The pinecone.ts file contains the IndexToPineconeHandler class used to index Notion content into a Pinecone database. The IndexToPineconeHandler class does the following:
- Communicates with Pinecone to create the required index.
- Uses Langchain’s
NotionAPILoaderto load content from a Notion workspace. - Converts this content into vector embeddings using OpenAI.
- Stores these vectors into our Pinecone index database using
PineconeStore.
Examine the content of pinecone.ts:
src/pinecone.ts// Import necessary libraries
import { NotionAPILoader } from "langchain/document_loaders/web/notionapi";
import { OpenAIEmbeddings } from "langchain/embeddings/openai"
import { PineconeClient } from "@pinecone-database/pinecone";
import { PineconeStore } from "langchain/vectorstores/pinecone";
// Define the class for indexing into Pinecone
class IndexToPineconeHandler { VECTOR_SIZE = 1536; // Define vector size constant #env: Record<string, string> = {}; // Initialize a private environment variable pinecone = new PineconeClient(); // Initialize a Pinecone client
This first part imports the necessary libraries for fetching and processing data from Notion, converting it into vector embeddings with OpenAI, and storing it in Pinecone database. The class IndexToPineconeHandler handles indexing Notion content to Pinecone.
src/pinecone.ts async createIndex(dimension) { const indexes = await this.pinecone.listIndexes() const index = indexes.find(i => i === this.#env.PINECONE_INDEX_NAME)
if (!index) { console.log("Existing index not found. Creating a new index.") const createRequest = { name: this.#env.PINECONE_INDEX_NAME, dimension, metric: "euclidean", } await this.pinecone.createIndex({ createRequest }) console.log("Your index has been created. Please wait a few minutes for it to become ready... document creation may fail in the meantime.") } else { console.log("Existing index found. Skipping index creation.") } }
The createIndex() function checks for an existing index in Pinecone and, if none exists, creates a new one. The createIndex() function makes use of the dimension argument to define the number of dimensions in the vector space of the index. If the index the createIndex() function is looking for is already in Pinecone, the function skips the creation step.
src/pinecone.ts async generatePineconeDocumentsForNotion() { console.log("Loading documents from Notion...")
const pageLoader = new NotionAPILoader({ clientOptions: { auth: this.#env.NOTION_INTEGRATION_TOKEN }, id: this.#env.NOTION_PAGE_ID, type: "page", });
const pageDocs = await pageLoader.loadAndSplit();
console.log(`Loaded ${pageDocs.length} documents from Notion.`)
const pineconeIndex = this.pinecone.Index(this.#env.PINECONE_INDEX_NAME) const res = await PineconeStore.fromDocuments( pageDocs, new OpenAIEmbeddings({ openAIApiKey: this.#env.OPENAI_API_KEY, }), { pineconeIndex } );
console.log(`Created documents in Pinecone.`)
return res }
The generatePineconeDocumentsForNotion() function loads pages from Notion using the Notion API. This produces a number of pages which are then loaded and split using Langchain.
This function is the most complex part of this process, and explaining how it works in detail is out of scope for this tutorial. In short, the function takes the content in Notion and splits it into smaller documents, which are then converted into vector embeddings using OpenAI. These vector embeddings are then stored in Pinecone.
src/pinecone.ts async handle(request: Request, env, ctx) { this.#env = env;
const unauthorized = () => new Response("Unauthorized", { status: 401 })
const authHeader = request.headers.get("Authorization") const authToken = this.#env.AUTHORIZATION
if (authToken && !authHeader) return unauthorized()
if (authHeader && authToken) { const parsedBearer = authHeader.split("Bearer ")[1] if (parsedBearer !== authToken) return unauthorized() }
await this.pinecone.init({ environment: this.#env.PINECONE_ENVIRONMENT, apiKey: this.#env.PINECONE_API_KEY, });
await this.createIndex(this.VECTOR_SIZE) await this.generatePineconeDocumentsForNotion()
return new Response("Done!") }
}
export const IndexToPinecone = (request, env, ctx) => { const handler = new IndexToPineconeHandler(); return handler.handle(request, env, ctx);
}
Finally, the handle() function is the entry point of the IndexToPineconeHandler class. The handle() function first validates the incoming request to check if the user is authorized. If the user is not authorized, the handle() function returns an HTTP 401 Unauthorized response. If the user is authorized, the handle() function initializes the Pinecone client, creates an index in Pinecone, loads pages from Notion, transforms these pages into vectors, and stores these vector embeddings into the Pinecone index. The function returns a Done message once these steps are completed.
The last part of the code exports a function IndexToPinecone as a handler which invokes the handle() function of an instantiated IndexToPineconeHandler class object. The IndexToPinecone function is what is being used in the main Worker code to handle requests related to indexing the Notion content into Pinecone.
5. Query content using Langchain and Pinecone
The search.ts file implements the GetSearch class designed to provide search functionality to the Notion database indexed in Pinecone. It interacts with OpenAI and Pinecone to query the indexed content from your Notion workspace.
In the content of search.ts, the TypeScript module defines a class GetSearch that extends the OpenAPIRoute class from the @cloudflare/itty-router-openapi library. The main purpose of this GetSearch class is to provide a specific API route that handles and responds to user queries with relevant content from Notion pages that have been indexed into Pinecone database.
src/search.ts// Importing necessary libraries
import { OpenAI } from "langchain/llms/openai";
import { OpenAIEmbeddings } from "langchain/embeddings/openai"
import { OpenAPIRoute, Query } from "@cloudflare/itty-router-openapi";
import { PineconeClient } from "@pinecone-database/pinecone";
import { PineconeStore } from "langchain/vectorstores/pinecone";
import { VectorDBQAChain } from "langchain/chains";
These are the necessary libraries for the GetSearch class to interact with OpenAI, Pinecone, and Langchain. It also uses the OpenAPIRoute class from the @cloudflare/itty-router-openapi library to define an OpenAPI-compliant API route, which is necessary for a ChatGPT plugin.
src/search.tsexport class GetSearch extends OpenAPIRoute { static schema = { // OpenAPI schema defining the tags, summary, parameters, and responses for this route };
In the above code block, GetSearch extends OpenAPIRoute, which means it inherits methods and properties from the OpenAPIRoute class. The schema object indicates the tags, summary, parameters, and responses for this route.
src/search.tsasync handle(request: Request, env, ctx, data: Record<string, any>) { // Instantiates a new Pinecone client and initializes it with the environment and API key const pinecone = new PineconeClient();
await pinecone.init({ environment: env.PINECONE_ENVIRONMENT, apiKey: env.PINECONE_API_KEY, }); //... the rest of the code
}
The handle() method in the above code block is where the main functionality happens. The handle() method is an asynchronous function that gets triggered when a request hits the registered API route. The handle() method first initializes the Pinecone client, and then fetches necessary information from the request and environment variables.
src/search.tsconst pineconeIndex = pinecone.Index(env.PINECONE_INDEX_NAME)
const vectorStore = await PineconeStore.fromExistingIndex( new OpenAIEmbeddings({ openAIApiKey: env.OPENAI_API_KEY }), { pineconeIndex }
);
In the above code block, the Pinecone index is retrieved and then used to create a VectorStore from the existing index. This VectorStore will be used to perform searches in the vector database.
src/search.tsconst model = new OpenAI({ openAIApiKey: env.OPENAI_API_KEY,
});
const chain = VectorDBQAChain.fromLLM(model, vectorStore, { k: 10, returnSourceDocuments: true,
});
In the above code block, a new instance of Langchain’s OpenAI LLM (Large Language Model) interface is initialized using the OpenAI API key. This is combined with the vectorStore to initialize a Vector Database Query Chain. Explaining the functionality of this chain is out of scope, but it can be thought of as an interface to correctly send formatted queries to the Pinecone database.
src/search.tsconst response = await chain.call({ query: data.q });
return new Response(JSON.stringify(response), { headers: { "content-type": "application/json" },
});
Finally, the query from the client request is passed to the query chain, the results are converted to JSON string, and the result is returned as a response. This allows users to make queries against the Notion workspace that has been pre-processed and stored in Pinecone.
6. Add the indexing and search routes
Now that you have created the indexing and search functionality, you will need to add the routes to your application, using the index.ts file.
The imported GetSearch from “./search” and IndexToPinecone from ‘./pinecone’ are classes that each define a different route handler for the API.
Below is a breakdown of each part of the code:
src/index.ts// Import necessary libraries and route handlers
import { OpenAPIRouter } from "@cloudflare/itty-router-openapi";
import { GetSearch } from "./search";
import { IndexToPinecone } from './pinecone'
The code above first imports the necessary libraries. OpenAPIRouter is a function for creating open API routers, GetSearch and IndexToPinecone are two route handlers that have been defined earlier in other modules.
src/index.ts// Create a default router with some descriptions
export const router = OpenAPIRouter({ schema: { info: { title: "Notion Search", description: "A plugin that allows the user to index their Notion workspace and query it", version: "v0.0.1", }, }, docs_url: "/", aiPlugin: { name_for_human: "Notion Search", name_for_model: "notionsearch", description_for_human: "Notion Workspace Search", description_for_model: "Query your Notion workspace from ChatGPT.", contact_email: "support@example.com", legal_info_url: "http://www.example.com/legal", logo_url: "https://workers.cloudflare.com/resources/logo/logo.svg", },
});
The part above creates a new OpenAPIRouter instance and defines the schema, documentation URL and plugin properties using a configuration object.
src/index.ts// Define routesrouter.get("/search", GetSearch); // Search methodrouter.original.get("/pinecone", IndexToPinecone); // Indexing method
// 404 for everything elserouter.all("*", () => new Response("Not Found.", { status: 404 }));
The section above defines one GET route for each of the imported handlers. Whenever a GET request is sent to YOUR_WORKER_URL/search, it will pass the request to GetSearch handler. Similarly, YOUR_WORKER_URL/pinecone is handled by IndexToPinecone. Any other routes will result in a Not Found message with HTTP status code 404.
src/index.ts// Export default handler
export default { fetch: router.handle,
};
This part exports the router’s handle method as a fetch method, which makes this router usable as Worker code. fetch is a default entry point for Cloudflare workers, where incoming fetch events will be passed in to be handled by the router.
7. Deploy your Worker application
Once you have created your Worker application and added the required functions, deploy the application.
Before you deploy, initialize a number of secret values for your application. For each of the following values, run the npx wrangler secret put command:
$ npx wrangler secret put <SECRET_NAME>
AUTHORIZATION(optional): An optional authorization token that can be used to secure your application. If you do not want to use this, you can leave it blank.NOTION_INTEGRATION_TOKEN: The Notion integration token you created in step three.NOTION_PAGE_ID: The ID of the Notion page you want to index.OPENAI_API_KEY: Your OpenAI API key you can find on the API Keys page.PINECONE_API_KEY: The Pinecone API key you created in step two.PINECONE_ENVIRONMENT: The environment that Pinecone deploys to.PINECONE_INDEX_NAME: The name of the Pinecone index you created in step two.
To deploy your Worker application to the Cloudflare global network:
- Make sure you are in your Worker project’s directory, then run the
npx wrangler deploycommand:
$ npx wrangler deploy
Wrangler will package and upload your code.
After your application is deployed, Wrangler will provide you with your Worker’s URL.
Now your Notion Workspace is available and searchable via the provided Workers URL.
8. Add the plugin to ChatGPT
ChatGPT Plugins, which are in alpha, allow you to augment ChatGPT’s functionality with custom functionality. When it is appropriate, ChatGPT will query your plugin to provide additional information to the user.
To add a new ChatGPT plugin:
- Log in to ChatGPT.
- Select the Alpha option at the top of ChatGPT’s dashboard for the model option.
- Select Plugins.
- A new button appear with the text
No plugins enabled. Select this button and select the Plugin store option.
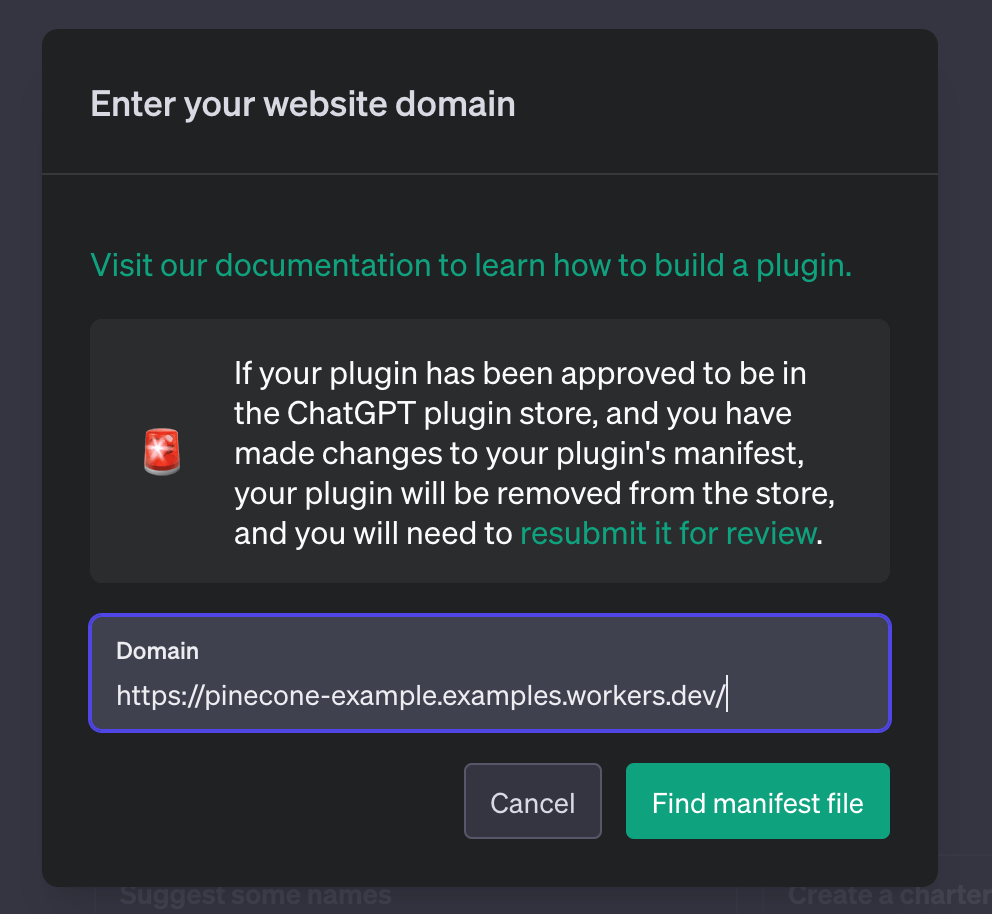
In the new modal popup, select Develop your own plugin. This will allow you to enter a custom plugin URL and use your own plugins directly in ChatGPT. Enter the deployed Workers URL, as seen below:
Next steps
To build more with Workers, refer to Tutorials.
If you have any questions, need assistance, or would like to share your project, join the Cloudflare Developer community on Discord to connect with other developers and the Cloudflare team.